随着大数据时代的到来,网络舆情在数据体量、复杂性和产生速度等方面发生巨大变化。网络舆论引导方法已超出了现有常用的框架。习近平总书记在全国宣传思想工作会议上提出,宣传思想工作创新,重点要抓好理念创新、手段创新。网络舆情是网络舆论引导工作的基础和晴雨表,以大数据观念变革传统网络舆论引导思维,准确把握网络舆情的内在特征及其在演化过程中的潜在规律,对于新形势下做好网络舆论引导工作,维护网络社会安全,具有重要的理论意义和实践价值。

一、大数据在网络舆论引导中的价值
大数据是指无法在一定时间内用常规软件工具进行抓取、管理和处理的数据集合,必须通过深度挖掘、计算、分析才能创造价值的海量信息。大数据的价值不在信息本身,而在于通过分析数据关联性预测未来。网络舆论引导的前提是网络舆情的预测,而大数据技术为网络舆情的预测提供了支撑和保证。
(一)大数据价值的核心:舆情预测
传统网络舆论引导工作的起点,是对已发生的网络舆情进行监测开始。然而这种方式的局限在于滞后性。
大数据技术的应用,就是挖掘、分析网络舆情相关联的数据,将监测的目标时间点提前到敏感消息进行网络传播的
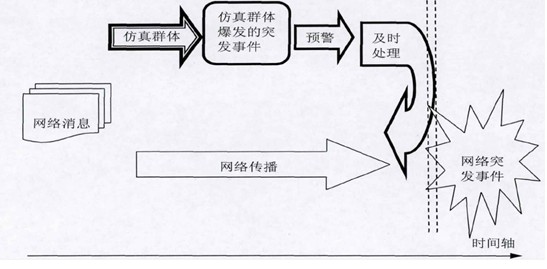
初期,通过建立的模型,模拟仿真实际网络舆情演变过程,实现对网络突发舆情的预测。
(二)大数据价值的条件:舆情全面
大数据技术要预测舆情,首要条件是对各种关联的全面数据进行分析计算。传统数据时代,分析网民观点或舆情走势时,只关注网民跟帖态度和情绪,忽视了网民心理的变化;只关注文本信息,而较少关注图像、视频、语音等内容;只观察舆论局部变化,忽视其他群体的舆论变化;只解读网民文字内容,而忽视复杂多变的社会关系网络。从舆情分析角度看,网民仅仅是信息海洋中的"孤独僵尸",犹如蚁群能够涌现高度智能,而单个蚂蚁如附热锅到处乱窜。
大数据时代,突破了传统数据时代片面化、单一化、静态化的思维,开始立体化、全局化、动态化研究网络舆情数据,将看似无关紧要的舆情数据纳入分析计算的范围。
(三)大数据价值的基础:舆情量化
大数据预测舆情的价值实现,必须建立在对已挖掘出的海量信息,利用数学模型进行科学计算分析的基础之上,其前提是各类相关数据的量化,即一切舆情信息皆可量化。但数据量化,不等同于简单的数字化,而是数据的可计算化。要在关注网民言论的同时,统计持此意见的人群数量;在解读网民言论文字内容的同时,计算网民互动的社会关系网络数量;对于网民情绪的变化,可通过量化的指标进行标识等。
(四)大数据价值的关键:舆情关联
数据背后是网络,网络背后是人,研究网络数据实际上是研究人组成的社会网络。大数据技术预测舆情的价值实现,最关键的技术就是对舆情间的关系进行关联,将不再仅仅关注传统意义上的因果关系,更多关注数据间的相关关系。按大数据思维,每一个数据都是一个节点,可无限次地与其他关联数据形成舆情链上的乘法效应--类似微博裂变传播路径,数据裂变式的关联状态蕴含着无限可能性。
二、目前网络舆情工作的主要瓶颈
近年来,各地高度重视网络舆情工作,通过创新机制、提升技术、人才培养等多种方式,不断提高舆情工作水平和能力,有效应对了各种重大网络突发事件,有力维护了社会稳定。但与日益频繁和繁重的网络舆情监测任务,与新时期网络舆情监测向网络舆情预测转型的任务相比,还存在着技术、人才和制度瓶颈。
(一)技术瓶颈
目前,各地舆情监测工作的主要手段仍以人工检索为主,尽管也使用了市面相对成熟的相关搜索软件进行辅助搜索,但搜索舆情的技术仍采用传统的二维搜索方式,即主题关键词和网络平台二维坐标,由舆情员对采集的信息进行二次加工成舆情产品。
但搜索的舆情信息结果多为一级文本信息,对于深层次的多级舆情信息,如新闻、微博后的评论,网民的社会关系,网民针对某一事件评论反映出的情绪变化,以及网民煽动性、行动性的言论、暗示等数据无法深度挖掘,仍靠人工采集和分析判断。受制于舆情员的知识水平和价值判断的不同,极有可能导致有价值的舆情信息丢失,无法准确及时预测舆情走势,大大降低了舆情监测工作的效率、准确性,增加了有价值舆情信息发现的偶然性和投机性,为重大突发事件的舆情预测埋下隐患。
(二)人才瓶颈
近年来,各地加大舆情监测人员配备,经过实践锻炼和培训,舆情工作人员基本掌握了舆情监测的业务技巧和软件使用技巧,日常网络舆情监测任务基本满足需求,基本能够确保日常浅层舆情信息的发现和上报。但要实现对舆情信息的深度挖掘和分析,实现舆情信息的预测,现有舆情工作人员的水平严重滞后,亟需建立一支精通大数据挖掘分析、模型构建等类的专业人才队伍。
(三)制度瓶颈
按照大数据挖掘技术原理,要实现对舆情数据的深度挖掘,需掌握大量的数据,分析网民情绪变化、社会关系等,推算其阶段性行动倾向和轨迹。根据现行制度框架,这些数据将遇到制度性的瓶颈。
三、大数据思维对网络舆论引导工作的启示
当前,应实现网络舆论引导工作由舆情监测向舆情预测转型,由事发舆论引导向舆论引导前置转型,大数据技术为这种转型提供了可能和动力。对网络舆论引导的启示可总结为"四个转变"。
(一)由抽取舆情信息样本向掌握全部舆情数据转变
按照大数据的概念,现有的传统舆情监测方式采集的舆情信息仅为样本信息。通过大数据技术,突破传统舆情监测技术瓶颈,深度挖掘目标舆情相关的所有看似不相干的数据信息,如兴趣爱好、学历水平、体貌特征、社会关系等尽可能全面的数据,为全面分析舆情走向提供基础。
(二)由追求舆情信息精确性向舆情信息混杂性转变
大数据的一个重要特征是数据的混杂性,因此我们不仅要接受多样化的数据,还要善于利用多样化的数据,将不同领域数据关联起来进行分析。不再仅仅关注于网民在几点几分发表了什么言论,而要关注在某一时间范围,网民的关注人群、关注内容、关注方式的变化,以及他对周围其他人的影响等数据。
(三)由推算舆情因果关系向计算舆情相关关系转变
改变传统的"有罪推论"的舆情监测逻辑理念,不再单纯寻找舆情数据间的因果关系,如新浪微博有关突发事件串联上街游行言论的原因和后果,更多关注与此类言论相关联的电话、微信、QQ等通联手段信息、上街游行口号等衍生数据,拓展舆情监测、处置视角,为预测舆情走向赢得时间和空间。
(四)由定性推算舆情信息向量化计算舆情信息转变
量化舆情不等同于简单的数字化舆情。要将所有相关联的舆情信息,通过已建立的标准指标体系进行量化处理,将感性的网民评论、情绪变化、社会关系等信息,以量化的形式转化为可供计算分析的标准数据,通过数据模型进行计算预测舆情走向。
四、运用大数据思维做好网络舆论引导工作的对策建议
大数据时代已全面到来,面对纷繁复杂的舆情工作形势,唯有大数据技术才是提升网络舆论引导工作水平的"核武器"。
(一)优化大数据技术支撑平台
加强与科研院所的合作,进一步研发大数据深度挖掘、存储、计算和分析的关键技术,研发补充多种类型的业务功能模块,不断优化网络舆情信息处理技术平台支撑功能,加大舆情计算分析能力,将其打造为络舆情大数据处理中央平台。
(二)引进培养大数据技术人才
系统梳理网络舆情工作所需技术人才目录,通过招考、聘用等方式,引进亟需数据挖掘、分析人才;通过委托高校培养等方式,培养已有专业技术人才;通过购买服务的方式,短期租赁高精尖大数据技术人才为我所用,不断健全大数据技术人才体系。
(三)研究制定舆情量化指标体系
组织专门课题组,与舆情专业机构合作,以历史积累的舆情案例为素材,系统梳理网络舆论引导业务流程,建立可供量化的舆情指标体系,将网民情绪变化、社会关系、意见倾向、意见影响力等定性内容纳入指标体系,并不断完善。细分舆情类别,有针对性地构建舆情预测模型,按照量化指标体系标准全面计算分析舆情内容,有效预测突发网络舆情发生。
(四)拓宽大数据挖掘获取渠道
在加快研发数据挖掘技术同时,加大与人民网、新浪、腾讯、百度、凤凰网等主要网站的合作,通过合作模式获取后台关键数据。健全网络舆情信息历史数据沉淀机制,将重要关键的网络舆情数据归类存储,运用大数据技术进行多次价值开发。建立健全全市大舆情工作机制,制定舆情大数据工作体系,完善市级部门、区(市)县、媒体、社会举报、民意调查、社保、社会信用、工商等舆情数据获取方式,拓宽大数据获取的渠道。
(五)再造舆论引导业务流程
按照大数据业务需求,再造网络舆情监测、引导、处置等舆论引导业务流程,以全程化、全员化、全媒化和规范化的思路,实现网络舆情预测和网络舆论引导前置。
五、数据挖掘技术在舆论引导工作中的路径选择
大数据技术的核心技术是数据挖掘技术。要使数据挖掘技术有效助力网络舆情监测与引导,首先应根据网络舆情演化规律,构建适用于网络舆情挖掘分析的相关模型和技术方法,使之满足网络等复杂系统中不同舆情对象间的复杂关系分析,从而为网络舆情挖掘线路与进程提供理论基础,实现一般数据挖掘模型和技术方法与网络舆情挖掘与分析的有机融合。数据挖掘技术在网络舆情引导中的应用可从以下四个方面展开。
(一)网络舆情关联分析
舆情关联关系是网络舆情数据库中存在的一类重要的、可被发现的知识,首先需要分析网络事件表征参数间关系,进而发现网络舆情中隐藏的舆情关联。为更准确表示网络舆情间的关联度,引入网络舆情支持度和网络舆情可信度来量化网络舆情关联规则的相关性,从而使挖掘结果更准确。如,基于网络舆情关联规则挖掘,分析新浪微博中活跃者间关联强度、坚定支持者人数以及坚定支持者成员的变化频度等三个时间序列间的关联规则,挖掘出新浪微博舆情的关联关系,进而为舆情分析提供重要依据。
(二)网络舆情级别划分
网络舆情级别划分是根据网络舆情的特征判断该舆情的严重程度。在对网络舆情进行级别划分时,首先需要构造网络舆情分类器,然后利用分类器给未知类别的网络舆情赋予类别。构造分类器的过程一般包括训练与测试两个阶段。在训练阶段,建立模型描述预定的网络舆情集的特征,集合中的每一条舆情信息都属于一个预先给定的类别(如一般严重),利用类标签属性来标识类别。用于创建模型的网络舆情集一般被称为训练集,可以用数学公式、分类规则、神经网络或判定树等模型来描述一个预先确定的舆情集合,即进行有监督的学习。在测试阶段,使用创建的模型在网络舆情测试集上进行预测,并将测试结果与实际值进行比较,利用测试集中被正确分类的舆情的百分比来估计模型的准确率。经过以上两个过程,便可以形成性能稳定、准确率较高的网络舆情分类模型。当新的未知类别的网络舆情出现后,便可以把该舆情的相关信息输入到分类模型中,然后由分类模型判断该舆情的严重程度。
(三)网络舆情聚类
网络舆情聚类分析是指事先不了解网络舆情集合中每一个网络舆情样本所属的程度级别,而是根据网络舆情的主要特征,如舆情发生时间、评论数量、传播频度等,把相同或相近特征的网络舆情归为一类,从而实现舆情聚类。在舆情聚类过程中,分在同一个簇里的舆情对象具有很高的相似性,而不同簇中的舆情对象之间的相似性非常低。所形成的每个舆情簇都可以看作一个舆情类,由它可以导出规则。与级别划分不同,聚类只对舆情数据进行分析,由于最初并不知道如何开始,所以训练舆情数据一般不提供级别标记,但是随着聚类过程不断推进,可以自动给不同舆情簇分配对应的舆情级别标记。
(四)网络舆情倾向性分析
网络舆情倾向性是指网民对客观事物或公共事件所蕴涵的感情、观点、态度和立场。网络舆情倾向性分析是指通过数据挖掘技术,自动将网络舆情所包含的褒贬因素挖掘出来,明确信息传播者的真正意图和倾向性。网络舆情倾向性分析主要包括基于语义的网络舆情倾向性分析与基于机器学习的网络舆情倾向性分析,目前在技术、方法与模型方面均有深入研究,主要包括序列模式挖掘方法、情感分析、主题分析等。通过这些技术方法,将网络舆情中丰富的情感倾向进行定性定量分析,及时掌握网络舆情变化趋势。在此基础上,通过对随时间持续变化的舆情进行分析,可以较好地把握网络舆情的演化规律。
六、结语
作为网络舆论引导的晴雨表,舆情监测是做好网络舆论引导工作的前提和基础。网络舆情的纷繁复杂性,需要我们运用大数据技术进行舆情预测。但,大数据技术基于计算机的智能运算,只能作为智能化的手段。网络舆情大数据源于互联网的开放、共享,我们不能仅仅凭借技术构建的大数据平台去打捞那些可能代表一个群体或一定数量级的"沉默的声音"。因为如果他们与网络隔绝,或者由于"沉默的螺旋"心理效应而不提供任何数据,那么我们所精心分析出的网络舆情实际上是不全面的,以此来指导社会管理是有偏差的。
因此,面对越来越繁重的网络舆论引导任务,仍然固守以往传统工作方式将愈来愈力不从心。但完全寄希望于大数据技术来实现对网上舆论的管控,解放人的辛苦劳动无疑将是天方夜谭。